Logistic Regression Analysis on distributed data sources is possible with Multi Party Computation. In this article we will share insights and examples on how to use it.
Many social problems require cooperation between multiple parties to find a solution. Consider for example, a scenario in healthcare in which several hospitals want to jointly investigate the effectiveness of a treatment, or a collaboration between a healthcare institution and a health insurer to better map healthcare costs.
These are often collaborations between parties with partially conflicting interests, and/or where the privacy of third parties (the patients in the above example) must be guaranteed.
It is now technically possible to process and analyze data under very strong mutual data privacy guarantees: namely without the cooperating parties having to disclose the data to each other, or to a third party. The cryptographic technique that makes this possible is called secure Multi-Party Computation (MPC).
In this post, we will discuss performing a logistic regression analysis using MPC, and what benefits this offers.
Logistic regression
(Binary) logistic regression is a statistical method with which a predictive model can be trained. This predicts the probability (a number between zero and one) of an outcome with two possibilities. For example, a model that predicts the probability that "the patient will survive a certain disease" based on a number of patient characteristics such as age, gender, whether the patient participates in sports on a weekly basis, and so on.
Training such a statistical model is based on a list of examples from the past; a list of patients who have had the disease in question, which contains for each patient the characteristics and the "dependent variable" (i.e. whether the patient survived the disease).
The trained model can then be used to predict for a new patient ("new" as in: a patient for whom the dependent variable is still an unknown person), based on the characteristics, what the probability is that the patient will survive the disease. It also allows you to investigate the degree of influence that a certain characteristic has on whether or not the patient survives the disease.
Secure multi-party calculation
Secure Multi-Party Computation (MPC) is a privacy technology that allows multiple parties to perform joint calculations on their combined data, in such a way that the inputs of the parties remains mutually secret; only the result of the calculation is known (to one or more designated parties). MPC has a strong theoretical foundation based on four decades of scientific research, and due to technological advances in computer and network hardware, MPC has been practically applicable for a number of years.
Combining patient attributes from multiple sources
Let's stick to the aforementioned survival rate example, but this time, consider the scenario in which multiple care parties are involved; all of whom have a customer relationship with the same group of patients, but each holding different characteristics about their patients. (In the literature, this is also called the "vertically partitioned data" scenario.) The parties would like to train a model based on the joint set of characteristics, without sharing this data among themselves (and without having to engage an external party to whom all source data is entrusted).
Assuming that each party has its data set available in tabular form, we first create a virtually linked table.
The word "virtual" here means that the data of the different parties is never physically brought together in one place, and it is therefore not possible for a party to "browse" the data of other parties.
To make an accurate link, we choose a unique characteristic of the patient that is known to all sources, for example the policy number. This "join" operation that is performed using secure MPC is similar in functionality to a SQL INNER JOIN that you apply to link tables from a relational database, but offers superior data privacy properties. None of the parties can learn information about the entered tables or about the resulting table, except for certain meta-data, such as the sizes of the tables and column names.

Combining two sources in MPC with the Virtual Data Lake, without revealing the underlying records.
Training the logistic-regression model and making predictions (model evaluation)
On the virtually combined dataset we can now train the logistic regression model, again by means of an MPC calculation.
The result is a trained model in the form of a list of model parameters; the number of parameters is equal to the number of characteristics trained on plus one additional "bias" parameter.
Then we can choose whether to keep these model parameters secret or reveal them; in the latter case, the model can be evaluated in the standard way (as in: without MPC) (to predict the survival rate of a new patient). However, we can also use MPC when evaluating the model. The advantage of this is that both the model parameters, which contain information about the patients from the training data, and the characteristics of the patient on which the model is evaluated, remain secret from the parties.
It is important to assess the quality of the trained model. This is typically done by applying the model to a test data set (where the dependent variable is known) and then calculating various relevant quality metrics. Such metrics can also be calculated entirely in MPC, which means that both the model parameters and the test dataset remain invisible.
Performance benchmarks
Roseman Labs develops proprietary MPC software with a strong focus on performance, so that our solution can also scale to larger datasets. One of the techniques we use to maximize modern server hardware is to parallelize calculations across multiple CPU cores.
In the figures below we show benchmark results of a setup with three MPC nodes (6-core x86 servers, mutual communication latency 3ms). The figures show the calculation time required for linking tables, training the logistic-regression model, and evaluating the model respectively. In each graph, the x-axis shows the number of rows in the table, while the y-axis shows the time in seconds.
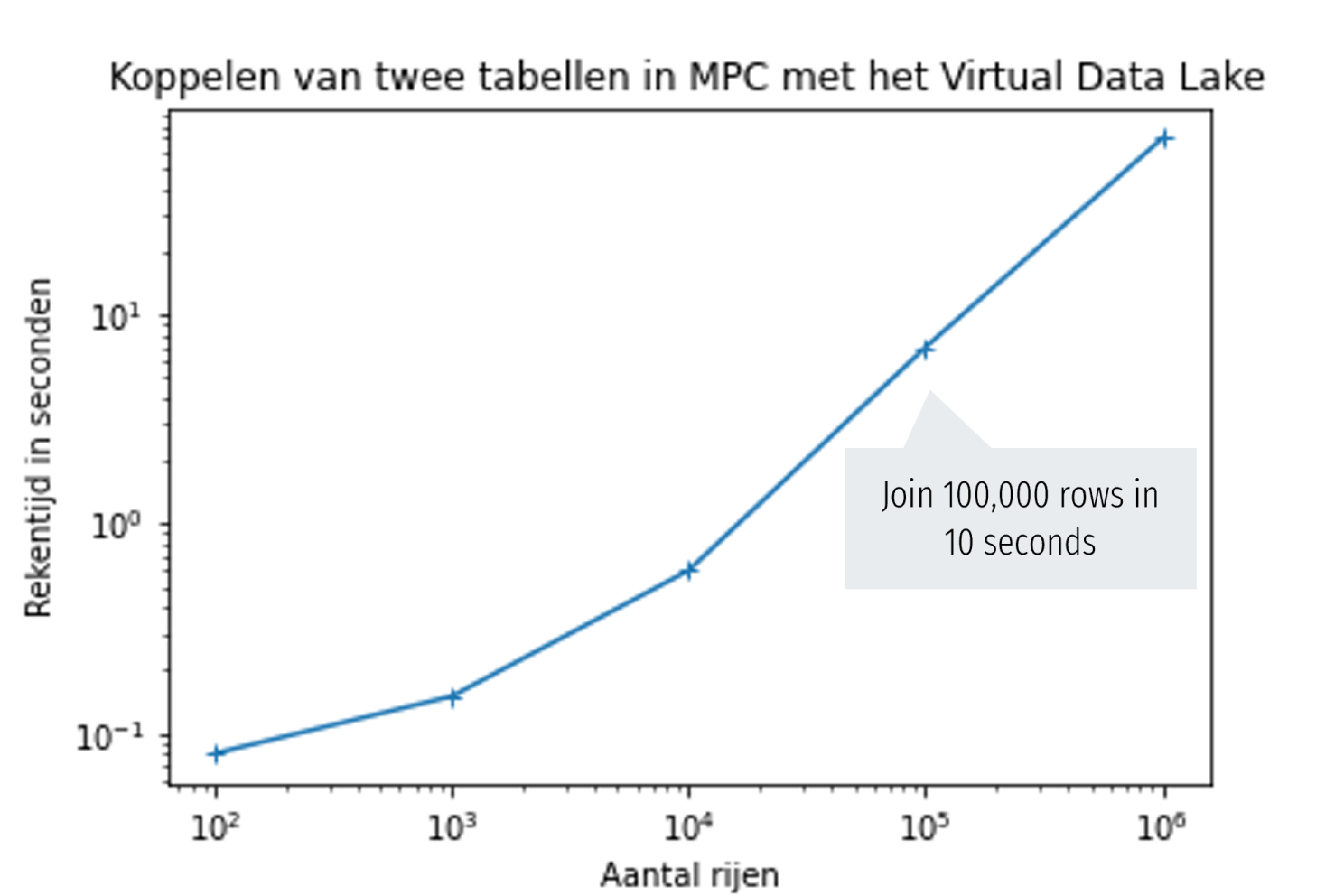

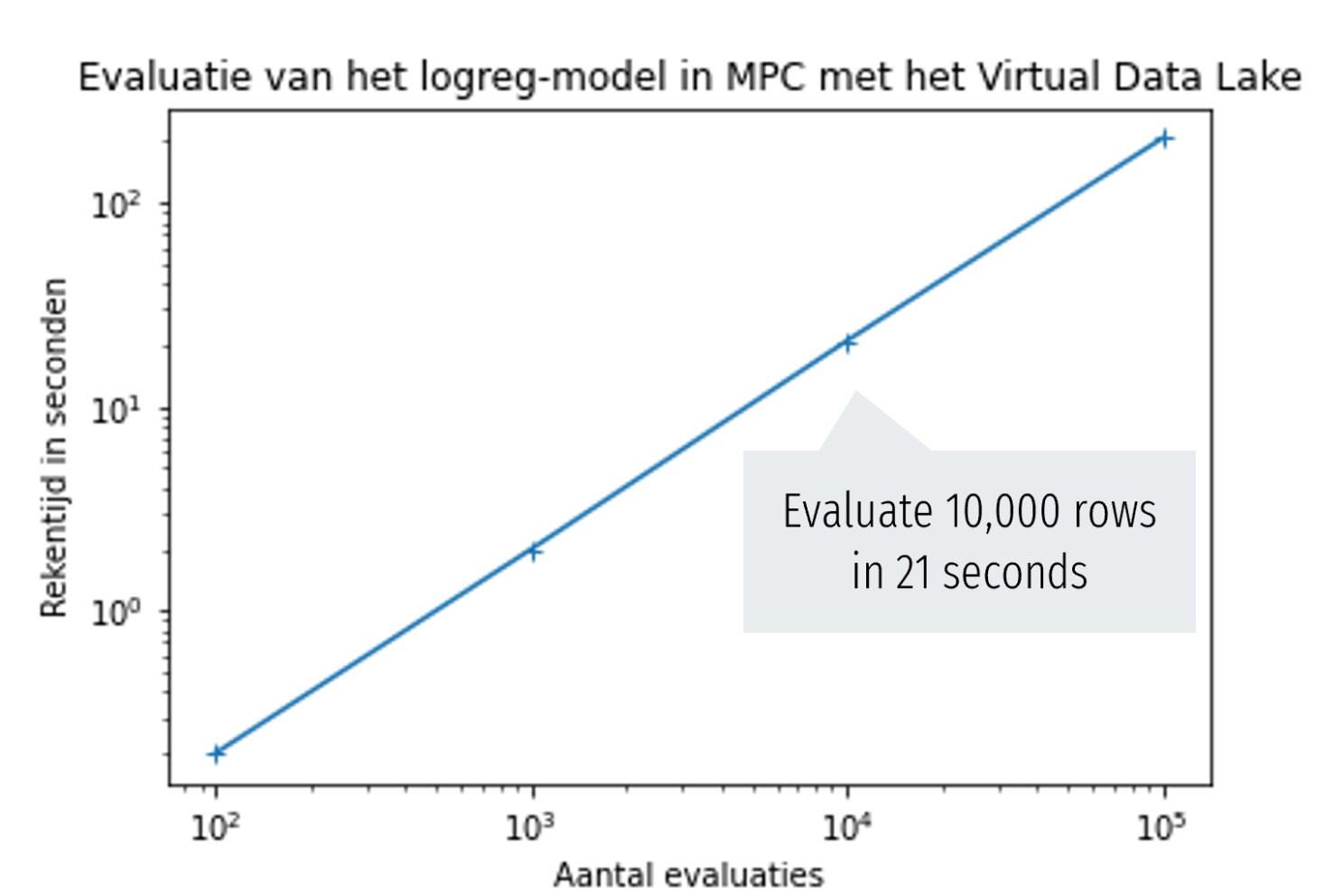
The graphs show that the calculation time increases linearly with the data volume. In addition (not visible in the graph), the computing time for most operations decreases linearly with the number of CPU cores used, which basically means that larger volumes of data can also be analyzed within a given deadline dictated by the application, by deploying enough CPU cores.